Archive for August 2015
Creating Histograms using matplotlib of Python [Hands-on]
Histogram is the best way to display frequency of a data and here we are to create one. So far we've dealt with text files and now it's time to show some progress and work with some real-world data hence this time, it's going to be a csv (comma-separated value) file from openflights.org.
Unlike text files, to process csv files, we need to import a package called csv . Also going forward in the program we need to calculate geo distance which is quite different from our normal distance calculation as the former deals with longitudes and latitudes so we've to download the python program geo_distance and import the function geo_distance into our program.
Let's dive deeper into the code. As you see below, we are working with two different input dataset 1. airports.dat to get airport details and 2. routes.dat to get route details. And now we've to calculate geo_distance from both those data and record it in a list distance[]
Now our data is ready and it's time for some storytelling. Let's create a histogram with hist().
Once you execute the code, a beautiful bluish histogram appears. Here it is:
 Download the source code here!
Download the source code here!
Unlike text files, to process csv files, we need to import a package called csv . Also going forward in the program we need to calculate geo distance which is quite different from our normal distance calculation as the former deals with longitudes and latitudes so we've to download the python program geo_distance and import the function geo_distance into our program.
import matplotlib.pyplot as plt import csv import geo_distance #for calculating dist b/w lats. and longs.
Let's dive deeper into the code. As you see below, we are working with two different input dataset 1. airports.dat to get airport details and 2. routes.dat to get route details. And now we've to calculate geo_distance from both those data and record it in a list distance[]
d = open("airports.dat.txt") latitudes = {} longitudes = {} distances = [] for row in csv.reader(d): airport_id = row[0] latitudes[airport_id] = float(row[6]) longitudes[airport_id] = float(row[7]) f = open("routes.dat") for row in csv.reader(f): source_airport = row[3] dest_airport = row[5] if source_airport in latitudes and dest_airport in latitudes: source_lat = latitudes[source_airport] source_long = longitudes[source_airport] dest_lat = latitudes[dest_airport] dest_long = longitudes[dest_airport] distances.append(geo_distance.distance(source_lat,source_long,dest_lat,dest_long))
Now our data is ready and it's time for some storytelling. Let's create a histogram with hist().
plt.hist(distances, 100, facecolor='b') plt.xlabel("Distance (km)") plt.ylabel("Number of flights")

Creating Charts using matplotlib in Python [Hands-on]
Data Storytelling is a very important branch of Data Science. Your world may not be as fond of numbers as you are hence it's very important to show them your results in the language that they understand. Hence for any language to be a member of the data science world, it's not only their data processing capabilities should be great but also the data visualizations should be exceptional and hence Python with packages like matplotlib is capable of competing in the world of R.
So let's try to represent the data of our previous post in terms of graphs/charts.
Problem:
Draw a bar graph with a dictionary counts that we built in our previous blogpost.
Takeaways:
Approach:
As we do for every new package, the first job is to import matplotlib package.
Now let's draw a bar graph with the values (vote) of the dictionary counts
Our graph is ready now but it's kind of naked (without labels ;) ) but let's show it!
 But a graph with no labels would make no sense to anyone hence it's our duty to make sure that the graph's x-axis and y-axis are labelled correctly. Let's add them too!
But a graph with no labels would make no sense to anyone hence it's our duty to make sure that the graph's x-axis and y-axis are labelled correctly. Let's add them too!
And here's how the bar graph looks: beautiful isn't?
 Download the source code here.
Download the source code here.
So let's try to represent the data of our previous post in terms of graphs/charts.
Problem:
Draw a bar graph with a dictionary counts that we built in our previous blogpost.
Takeaways:
- Basics of matplotlib
Approach:
As we do for every new package, the first job is to import matplotlib package.
import matplotlib.pyplot as plt
Now let's draw a bar graph with the values (vote) of the dictionary counts
plt.bar(range(len(counts)), counts.values(), align='center')
plt.show()

plt.ylabel(s = "Votes") plt.xticks(range(len(counts)), counts.keys(),rotation=90)
And here's how the bar graph looks: beautiful isn't?

Solving Voting Problem from OpenTechSchool with Python [Hands-on]
The best way to learn any programming language is to solve problems with it. While programming documentations can teach you syntax, you can get closer to the language only when you get hands-on with the code. So let's get started with our first problem in this python journey: Voting Problem
 Problem:
Problem:
We have 300 lines of survey data in the file radishsurvey.txt. Each line consists of a name, a hyphen, then a radish variety and so on. Our objective is to find answers for the following:
We have successfully built a dictionary with Radish variety as Key and Vote count as its Value and also we've handled the most important test case of printing the duplicate voters and disregarding their vote.
While this code can give us all the details that we wanted, we still manually need to go through every line to see the most voted and least voted variety. And we, programmers who are meant to be lazy, would want the program itself to tell us that too. Here's the code:
Here's the output after executing the code in python 2:
Our objectives are met and hope you've learnt something from this blogpost.
Download the entire python code here.
We have 300 lines of survey data in the file radishsurvey.txt. Each line consists of a name, a hyphen, then a radish variety and so on. Our objective is to find answers for the following:
- What's the most popular radish variety?
- What are the least popular?
- Did anyone vote twice?
Takeaways:
In our attempt to solve this problem, we'll come across the following concepts of python:
- Reading & Cleaning a text file
- Basic String Operations
- Traversing a Dictionary & List
- Iterative Looping and Conditional Looping
- Defining and Calling a function
Approach:
We can read the file radishsurvey.txt and put its contents in a file object to traverse it. Like this:
radish_contents = open("radishsurvey.txt") for line in radish_contents:
Instead we can directly use the file open() function in our iteration to reduce one step. But before that we are creating an empty dictionary counts to store the vote counts and an empty list voted to track the duplicate voters. Comments in the below code explain the purpose of every step.
counts = {} voted = [] for line in open("radishsurvey.txt"): line1 = line.strip() #print line #remove this comment to see how the line would be printed without strip() name, vote = line1.split(" - ") vote = vote.strip().capitalize() #just to make the 'vote' elements in proper case vote = vote.replace(" "," ") #data cleaning: replacing two white spaces with one if name in voted: print name, "has already voted" #printing the voter's name who voted again continue #skip their vote and process the next line voted.append(name) #for first time voters: adding their name to voted list if vote not in counts: # First vote for this variety - make a new entry in dictionary and set value to 1 counts[vote] = 1 else: # Increment the vote count as the entry is already present in the dictionary counts[vote] = counts[vote] + 1
for item in counts: print item, counts[item]
While this code can give us all the details that we wanted, we still manually need to go through every line to see the most voted and least voted variety. And we, programmers who are meant to be lazy, would want the program itself to tell us that too. Here's the code:
def find_winner(counts): winner = "" pre_vote = 0 for vote in counts: if counts[vote] >= pre_vote: winner = vote pre_vote = counts[vote] return winner, pre_vote def find_loser(counts): loser, pre_vote = find_winner(counts) #calling a function inside another fn. for vote in counts: if counts[vote] < pre_vote: loser = vote pre_vote = counts[vote] return loser, pre_vote
Here's the output after executing the code in python 2:
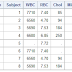
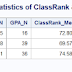
Phoebe Barwell has already voted Procopio Zito has already voted White icicle 64 Snow belle 63 Champion 76 Cherry belle 58 French breakfast 72 Daikon 63 Bunny tail 72 Sicily giant 57 Red king 56 Plum purple 56 April cross 72 And the winner is Mr. Champion with 76 votes Sorry, the loser is Mr. Red king with 56 votes
Our objectives are met and hope you've learnt something from this blogpost.
Download the entire python code here.